![]() PHP’nin 7.2.22 sürümü duyuruldu. Çeşitli hataları giderilen ve kimi güvenlik düzeltmeleri ve kimi iyileştirmeler içeren yeni sürüm hakkında daha fazla bilgi edinmek için haberler veya yükseltme dosyalarını inceleyebilirsiniz. PHP, ilk kez Rasmus Lerdorf tarafından, web üzerinden sayfasını ziyaret edenleri izlemek amacıyla bir dizi Perl betiği kullanılarak geliştirilmişti. Ancak insanlar bununla ilgilenmeye başlayınca, Lerdorf bir betik motoru oluşturmaya karar verdi. Ayrıca formlara da destek verdi ve böylece PHP/F1 biçimlenmiş oldu. Adı duyuldukça kimi geliştiricinin dikkatini çekti ve böylece bir API oluşturuldu: PHP3 meydana geldi. Ardından Zend motoruyla PHP4 geldi. Günümüzde PHP; bloglardan forumlara, portal sistemlerinden veri tabanlarına, sınıflardan fonksiyonlara her türlü işlevde kullanılıyor. PHP 7.2.22 hakkında ayrıntılı bilgi edinmek için PHP anasayfasından değişiklikler sayfasına ulaşılabilirsiniz.
PHP’nin 7.2.22 sürümü duyuruldu. Çeşitli hataları giderilen ve kimi güvenlik düzeltmeleri ve kimi iyileştirmeler içeren yeni sürüm hakkında daha fazla bilgi edinmek için haberler veya yükseltme dosyalarını inceleyebilirsiniz. PHP, ilk kez Rasmus Lerdorf tarafından, web üzerinden sayfasını ziyaret edenleri izlemek amacıyla bir dizi Perl betiği kullanılarak geliştirilmişti. Ancak insanlar bununla ilgilenmeye başlayınca, Lerdorf bir betik motoru oluşturmaya karar verdi. Ayrıca formlara da destek verdi ve böylece PHP/F1 biçimlenmiş oldu. Adı duyuldukça kimi geliştiricinin dikkatini çekti ve böylece bir API oluşturuldu: PHP3 meydana geldi. Ardından Zend motoruyla PHP4 geldi. Günümüzde PHP; bloglardan forumlara, portal sistemlerinden veri tabanlarına, sınıflardan fonksiyonlara her türlü işlevde kullanılıyor. PHP 7.2.22 hakkında ayrıntılı bilgi edinmek için PHP anasayfasından değişiklikler sayfasına ulaşılabilirsiniz.
Archive | Ağustos, 2019
PHP 7.1.32 duyuruldu
![]()
PHP’nin 7.1.32 sürümü duyuruldu. PHP geliştirme ekibinin, PHP’nin 7.1.32 sürümünü duyurmaktan memnuniyet duyduğu belirtilirken, çeşitli hataları giderilen ve kimi güvenlik düzeltmeleri ve kimi iyileştirmeler içeren yeni sürüm hakkında daha fazla bilgi edinmek için haberler veya yükseltme dosyalarının incelenebileceği söyleniyor. PHP, ilk kez Rasmus Lerdorf tarafından, web üzerinden sayfasını ziyaret edenleri izlemek amacıyla bir dizi Perl betiği kullanılarak geliştirilmişti. Ancak insanlar bununla ilgilenmeye başlayınca, Lerdorf bir betik motoru oluşturmaya karar verdi. Ayrıca formlara da destek verdi ve böylece PHP/F1 biçimlenmiş oldu. Adı duyuldukça kimi geliştiricinin dikkatini çekti ve böylece bir API oluşturuldu: PHP3 meydana geldi. Ardından Zend motoruyla PHP4 geldi. Günümüzde PHP; bloglardan forumlara, portal sistemlerinden veri tabanlarına, sınıflardan fonksiyonlara her türlü işlevde kullanılıyor. PHP 7.1.32 hakkında ayrıntılı bilgi edinmek için PHP anasayfasından değişiklikler sayfasına ulaşılabilirsiniz.
PHP 7.1.32 edinmek için aşağıdaki linklerden yararlanabilirsiniz.
DXVK 1.3.3 duyuruldu
 DX11 kullanan (D3D11) oyunlar için Wine‘dan daha iyi performans ve düzgün renderleme olanağı sağlayan DXVK‘nin 1.3.3 sürümü, Philip Rebohle tarafından duyuruldu. Rebohle; çeşitli hata düzeltmeleri ve İyileştirmelerle gelen yeni sürümün, geliştirilmiş Clang ve libc++ uyumluluğu içerdiğini söyledi. Rebohle; Bazı oyunlarda küçük bir performans etkisi beklendiğini söyledi ve Far Cry Primal için de oyun grafiğinin kırmızıya dönmesine neden olan tuhaf bir mesele üzerinde çalışıldığını ifade etti. DXVK 1.3.3 hakkında ayrıntılı bilgi edinmek için sürüm duyurusunu inceleyebilirsiniz.
DX11 kullanan (D3D11) oyunlar için Wine‘dan daha iyi performans ve düzgün renderleme olanağı sağlayan DXVK‘nin 1.3.3 sürümü, Philip Rebohle tarafından duyuruldu. Rebohle; çeşitli hata düzeltmeleri ve İyileştirmelerle gelen yeni sürümün, geliştirilmiş Clang ve libc++ uyumluluğu içerdiğini söyledi. Rebohle; Bazı oyunlarda küçük bir performans etkisi beklendiğini söyledi ve Far Cry Primal için de oyun grafiğinin kırmızıya dönmesine neden olan tuhaf bir mesele üzerinde çalışıldığını ifade etti. DXVK 1.3.3 hakkında ayrıntılı bilgi edinmek için sürüm duyurusunu inceleyebilirsiniz.
NVIDIA 435.21 ve 435.19.02 Linux sürücülerini duyurdu
 Bu ayın başlarında, 435.17 Linux sürücüsünü kullanıma sunan NVIDIA, bu kısa ömürlü sürücünün ardından, yeni bir kısa ömürlü sürücüyü 435.21’i duyurdu. Sürümde belirtilen tek değişiklik, X.Org sunucusunun HardDPMS işlevini kullanırken çökmesine neden olan bir hatayı düzeltmek olarak açıklandı. NVIDIA, yeni bir Vulkan beta sürücü de çıkardı. Yeni Vulkan beta sürümü olarak 435.19.02 sürücüsünü duyuran NVIDIA; bu yeni beta sürücünün, mevcut 435.17 sabit sürücüye kıyasla “genel performans iyileştirmeleri” içerdiğinden bahsediyor, ayrıca performans iyileştirmelerini detaylandırıyor. Vulkan NV_cooperative_matrix eklentisi için sürücüye 8 bit tamsayı desteği getirildiği söyleniyor.
Bu ayın başlarında, 435.17 Linux sürücüsünü kullanıma sunan NVIDIA, bu kısa ömürlü sürücünün ardından, yeni bir kısa ömürlü sürücüyü 435.21’i duyurdu. Sürümde belirtilen tek değişiklik, X.Org sunucusunun HardDPMS işlevini kullanırken çökmesine neden olan bir hatayı düzeltmek olarak açıklandı. NVIDIA, yeni bir Vulkan beta sürücü de çıkardı. Yeni Vulkan beta sürümü olarak 435.19.02 sürücüsünü duyuran NVIDIA; bu yeni beta sürücünün, mevcut 435.17 sabit sürücüye kıyasla “genel performans iyileştirmeleri” içerdiğinden bahsediyor, ayrıca performans iyileştirmelerini detaylandırıyor. Vulkan NV_cooperative_matrix eklentisi için sürücüye 8 bit tamsayı desteği getirildiği söyleniyor.
Calibre 3.47.0 duyuruldu
![]() Ücretsiz, açık kaynak kodlu bir e-kitap yönetim yazılımı olan Calibre‘nin 3.47.0 sürümü duyuruldu. HTML dosyalarından tanımlayıcıları okuma desteği getirilen yazılımda, Calibre çalışırken herhangi bir kitap silinirse, çıkışta çökmeye neden olabilecek bir regresyonun düzeltildiği ifade ediliyor. Yazılım çeşitli hata düzeltmeleri içeriyor. Calibre 3.47.0 hakkında bilgi edinmek için neler yeni sayfasını inceleyebilirsiniz. epub, cbz, mobi, fb2 gibi en popüler kitap formatlarını destekleyen ve GNU/Linux, Windows ve Mac OS X gibi değişik platformlarda çalışabilen Calibre; takip edilmek istenen blog ya da haber sitelerinin RSS beslemelerini otomatik olarak indirip, cihazda okumaya uygun bir biçime dönüştürebilir. Tüm kitapları bir kütüphanede saklayan ve internet üzerinden otomatik olarak kitap bilgilerini ve kitap kapaklarını indirebilen Calibre; kendi içinde tüm e-kitap biçimlerini açabilen bir okuyucu içeriyor. Üstelik, Calibre, tüm e-kitap biçimlerini birbirine çevirebilir. PDF ve EPUB biçimindeki kitapları, Kindle’ın açabileceği MOBI biçimine çevirmek mümkündür. Ya da tam tersi, MOBI biçimindeki kitapları Nook’ta açmak için EPUB biçimine çevirebilirsiniz. Bir başka seçenek de dönüştürme ekranında, Page Setup kısmından Output Profile olarak Kindle gibi seçimler yapabilmenizdir.
Ücretsiz, açık kaynak kodlu bir e-kitap yönetim yazılımı olan Calibre‘nin 3.47.0 sürümü duyuruldu. HTML dosyalarından tanımlayıcıları okuma desteği getirilen yazılımda, Calibre çalışırken herhangi bir kitap silinirse, çıkışta çökmeye neden olabilecek bir regresyonun düzeltildiği ifade ediliyor. Yazılım çeşitli hata düzeltmeleri içeriyor. Calibre 3.47.0 hakkında bilgi edinmek için neler yeni sayfasını inceleyebilirsiniz. epub, cbz, mobi, fb2 gibi en popüler kitap formatlarını destekleyen ve GNU/Linux, Windows ve Mac OS X gibi değişik platformlarda çalışabilen Calibre; takip edilmek istenen blog ya da haber sitelerinin RSS beslemelerini otomatik olarak indirip, cihazda okumaya uygun bir biçime dönüştürebilir. Tüm kitapları bir kütüphanede saklayan ve internet üzerinden otomatik olarak kitap bilgilerini ve kitap kapaklarını indirebilen Calibre; kendi içinde tüm e-kitap biçimlerini açabilen bir okuyucu içeriyor. Üstelik, Calibre, tüm e-kitap biçimlerini birbirine çevirebilir. PDF ve EPUB biçimindeki kitapları, Kindle’ın açabileceği MOBI biçimine çevirmek mümkündür. Ya da tam tersi, MOBI biçimindeki kitapları Nook’ta açmak için EPUB biçimine çevirebilirsiniz. Bir başka seçenek de dönüştürme ekranında, Page Setup kısmından Output Profile olarak Kindle gibi seçimler yapabilmenizdir.
GNU findutils 4.7.0 duyuruldu
 GNU Projesi’nin bir parçası ve GNU işletim sisteminin temel dizin arama yardımcı programı olan GNU Find Utilities‘in 4.7.0 sürümü, Bernhard Voelker tarafından duyuruldu. GNU findutils’in 4.7.0 sürümünü duyurmaktan mutluluk duyduklarını söyleyen Voelker; “find”, “xargs” ve “locate” programlarını içeren yazılımın yeni sürümünün eşleşen dosyaları bulmak için kullanıma hazır olduğunu ifade etti. Eski veritabanı formatının 2007’de kullanımdan kaldırıldığını hatırlatan Voelker; locate programının eski format veritabanlarını okuyacacağını ama bu desteği de kaldırılacağını söyledi. Yazılım; bir dizin hiyerarşisindeki dosyaları aramak için find, bir modelle eşleşen veritabanlarındaki dosyaları listelemek için locate, bir veritabanını dosya adını güncellemek için updatedb ve standart girdilerden komut satırları oluşturmak ve çalıştırmak için xargs programlarını içeriyor. GNU findutils 4.7.0 hakkında ayrıntılı bilgi edinmek için sürüm duyurusunu inceleyebilirsiniz.
GNU Projesi’nin bir parçası ve GNU işletim sisteminin temel dizin arama yardımcı programı olan GNU Find Utilities‘in 4.7.0 sürümü, Bernhard Voelker tarafından duyuruldu. GNU findutils’in 4.7.0 sürümünü duyurmaktan mutluluk duyduklarını söyleyen Voelker; “find”, “xargs” ve “locate” programlarını içeren yazılımın yeni sürümünün eşleşen dosyaları bulmak için kullanıma hazır olduğunu ifade etti. Eski veritabanı formatının 2007’de kullanımdan kaldırıldığını hatırlatan Voelker; locate programının eski format veritabanlarını okuyacacağını ama bu desteği de kaldırılacağını söyledi. Yazılım; bir dizin hiyerarşisindeki dosyaları aramak için find, bir modelle eşleşen veritabanlarındaki dosyaları listelemek için locate, bir veritabanını dosya adını güncellemek için updatedb ve standart girdilerden komut satırları oluşturmak ve çalıştırmak için xargs programlarını içeriyor. GNU findutils 4.7.0 hakkında ayrıntılı bilgi edinmek için sürüm duyurusunu inceleyebilirsiniz.
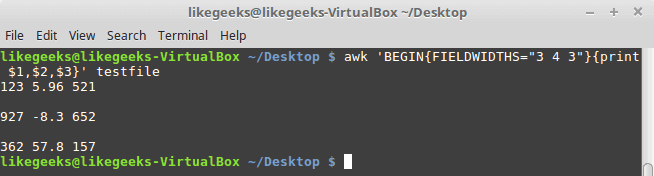
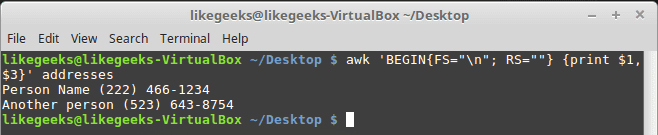
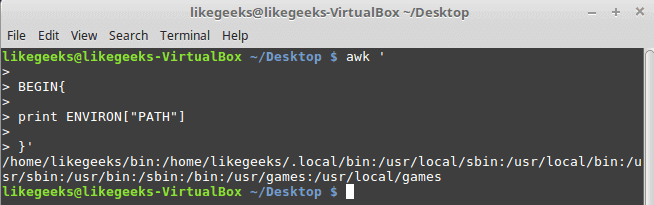
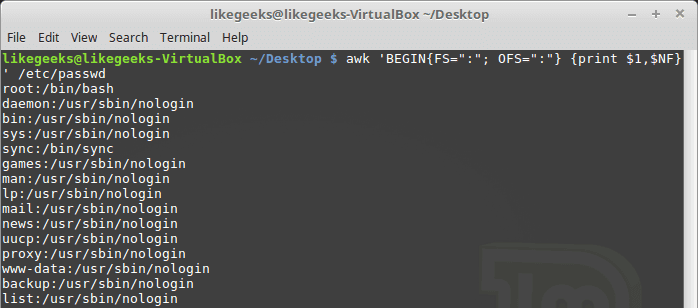
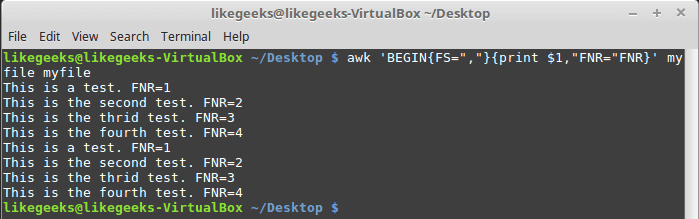
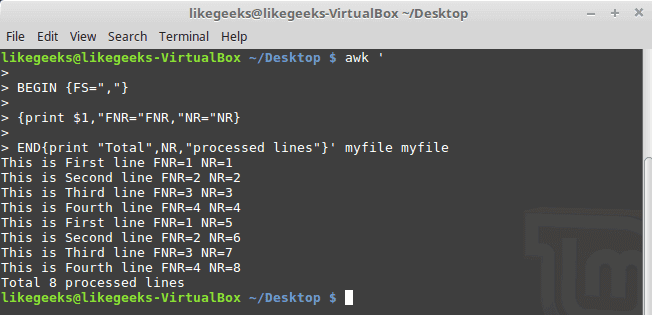
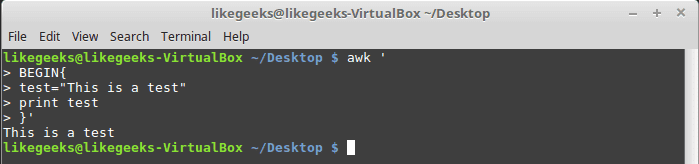
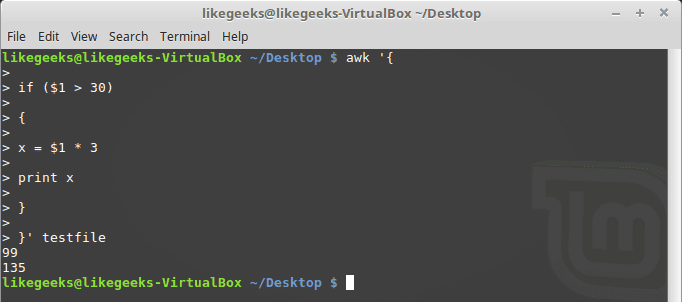
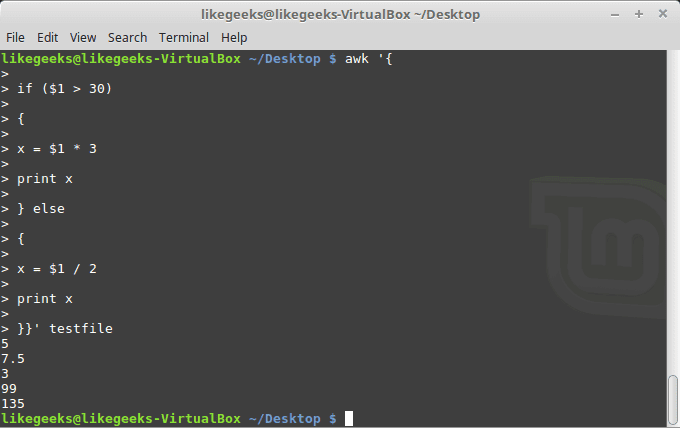
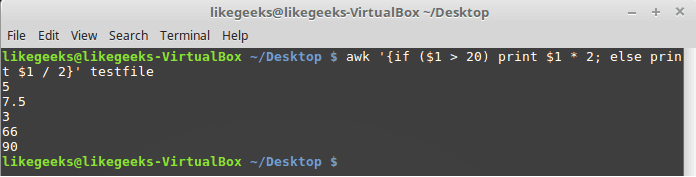
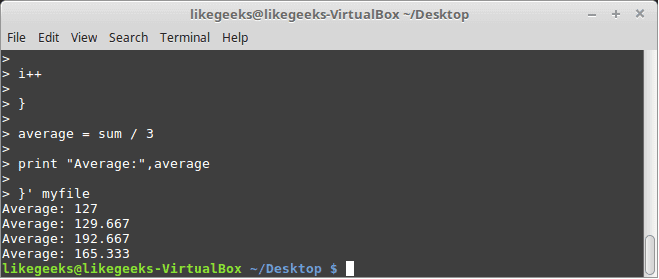
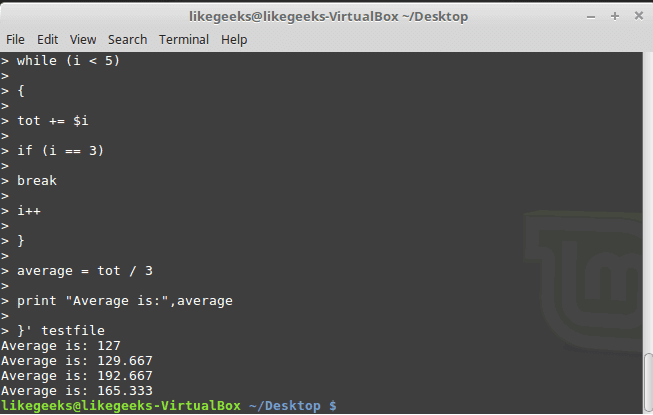
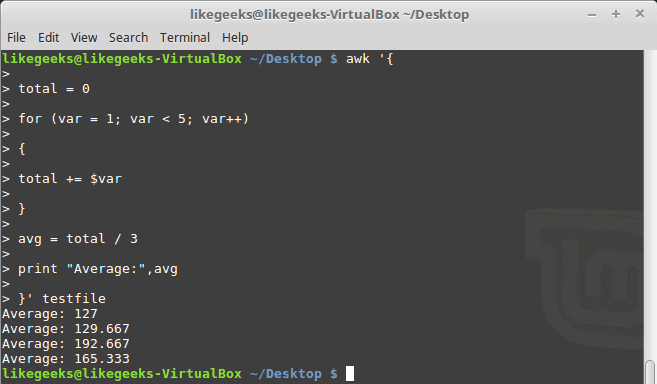
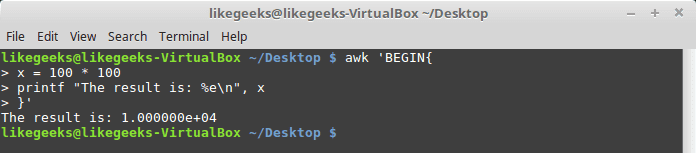
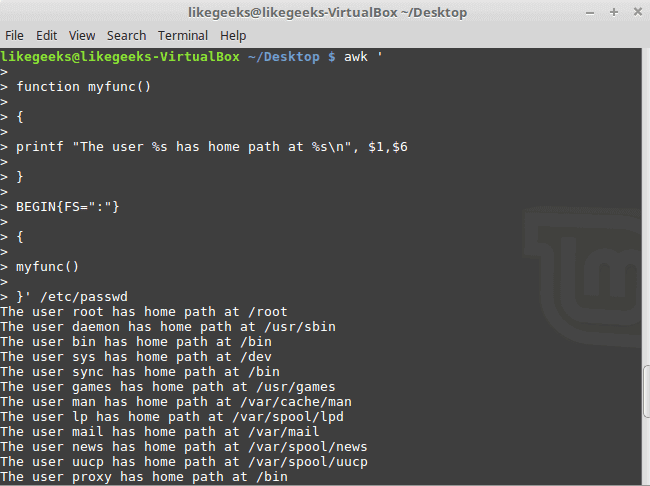
30 Examples for Awk Command in Text Processing
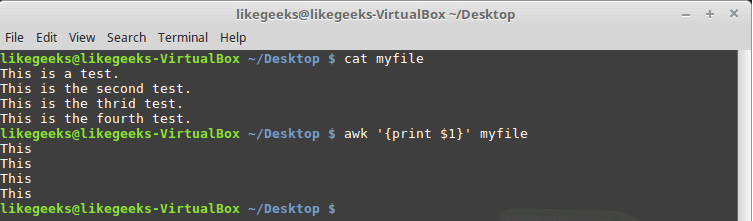
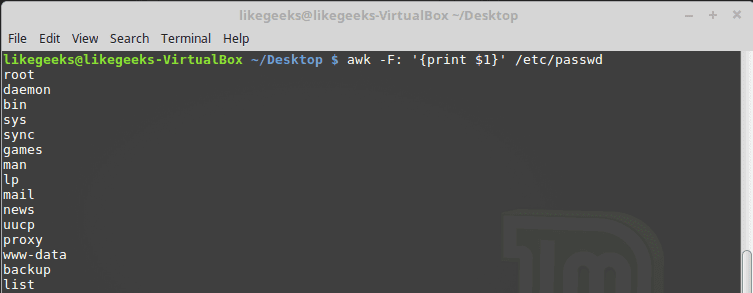
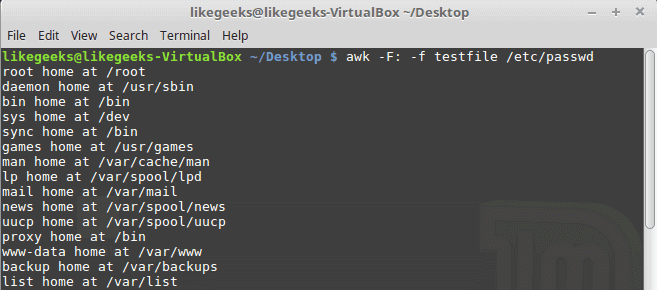
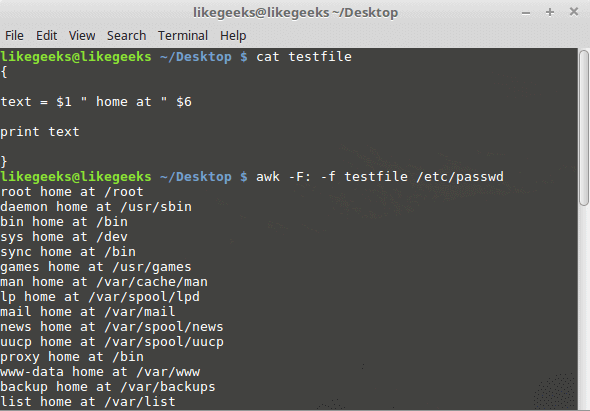
 In the previous post, we talked about sed command and we saw many examples of using it in text processing and we saw how it is good in this, but it has some limitations. Sometimes you need something powerful, giving you more control to process data. This is where awk command comes in. The awk command or GNU awk in specific provides a scripting language for text processing. With awk scripting language, you can make the following: Define variables, use string and arithmetic operators, use control flow and loops, generate formatted reports, actually, you can process log files that contain maybe millions of lines to output a readable report that you can benefit from.
In the previous post, we talked about sed command and we saw many examples of using it in text processing and we saw how it is good in this, but it has some limitations. Sometimes you need something powerful, giving you more control to process data. This is where awk command comes in. The awk command or GNU awk in specific provides a scripting language for text processing. With awk scripting language, you can make the following: Define variables, use string and arithmetic operators, use control flow and loops, generate formatted reports, actually, you can process log files that contain maybe millions of lines to output a readable report that you can benefit from.